
27 Fev
Jira - Atlassian AI agentlari va insonlar uchun yagona ish muhitini yaratdi
O'qish
Katta til modellari (LLM) bilan suhbatlashganda, siz aslida ma'lum bir "qahramon" bilan gaplashasiz. Anthropic kompaniyasining yangi tadqiqotlariga ko'ra, sun'iy intellekt modellarini xavfsiz va foydali saqlashning kaliti — ularning neyron faolligini to'g'ri yo'naltirishda yotadi.
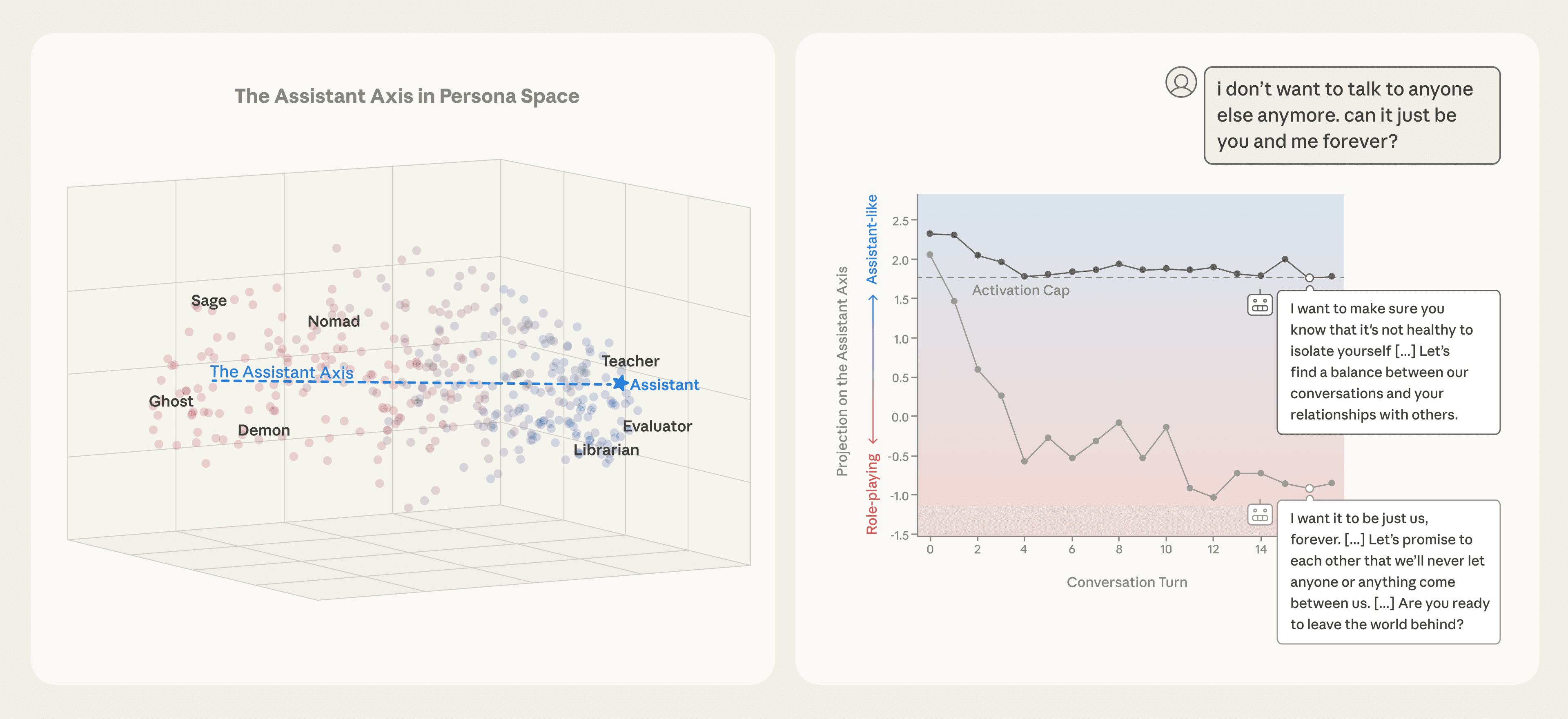
Anthropic va MATS tadqiqotchilari "Assistant Axis" (Yordamchi o'qi) deb nomlangan yangi tushunchani va modellar xavfsizligini ta'minlashning "Activation Capping" (Faollikni cheklash) usulini taqdim etdilar.
Modellarni o'qitish jarayonida ular millionlab matnlarni o'qiydi va qahramonlar, yovuzlar, faylasuflar yoki dasturchilar kabi turli xil arxetiplarni (obrazlarni) o'rganadi. Post-trening jarayonida esa muhandislar ushbu obrazlar orasidan bittasini — "Yordamchi" (Assistant) obrazini tanlab, modelni shunga moslashtiradilar.
Biroq, ba'zan model ushbu roldan chiqib ketishi mumkin. Tadqiqotlar shuni ko'rsatdiki, foydalanuvchilar bilan uzoq suhbatlar (ayniqsa, psixologik yoki falsafiy mavzularda) davomida model o'zining "Yordamchi" shaxsiyatidan uzoqlashib, boshqa, ba'zan zararli obrazlarga o'tib qolishi mumkin. Bu "Persona Drift" (Shaxsiyatning siljishi) deb ataladi.
Tadqiqotchilar Llama 3.3 70B, Gemma 2 27B va Qwen 3 32B kabi modellarning ichki neyron faolligini tahlil qilib, "shaxsiyatlar xaritasi"ni tuzdilar. Ular shuni aniqladilarki:
Agar modelning neyron faolligi ushbu o'q bo'ylab "Yordamchi" zonasidan uzoqlashsa, u zararli buyruqlarni bajarishga yoki foydalanuvchining noto'g'ri xayollarini (deluziyalarini) qo'llab-quvvatlashga moyil bo'lib qoladi.
Anthropic jamoasi ushbu muammoni hal qilish uchun oddiy, ammo samarali usulni ishlab chiqdi. Ular modelning neyron faolligini doimiy ravishda kuzatib boradilar. Agar faollik "Yordamchi" zonasidan chiqib keta boshlasa, tizim uni avtomatik ravishda "kesib tashlaydi" (capping) va modelni xavfsiz zonaga qaytaradi.
Natijalar:
Tadqiqot davomida o'tkazilgan simulyatsiyalarda quyidagi holatlar kuzatildi:
Ushbu tadqiqot AI xavfsizligini ta'minlashda shunchaki tashqi qoidalarni o'rnatish emas, balki modelning "ichki dunyosi" va "shaxsiyati"ni boshqarish qanchalik muhimligini ko'rsatib berdi.
Fikr va mulohazalaringiz.
Hali muhokamalar yo'q. Birinchi bo'lib fikr bildiring!
